今天闲来无事,就想接触一下爬虫的基本知识,搞大数据,没有数据是万万不可的,而数据的来源,有很大一部分是通过网络爬虫来抓取的。
关于爬虫,似乎python的框架会比较多,比如scrapy。不过刚开始接触,用python一些原生的库就可以完成一些简单的小爬虫程序了,就比如我刚刚写的冷笑话爬虫。
在这之前,得大概搞清楚爬虫的工作原理,其实也很简单。首先是对你的目标网站发出http请求,目标网站会返回一个html文档给你,也就是我们俗称的网页,原本,这些文档都是由一大堆标签构成的,但浏览器配合上css,js,就形成了我们看到的各种各样的网页。但我们的爬虫不需要这些外衣,我们只需要内容,所以爬虫接下来的工作是处理这个html文档,提取我们要的信息,然后继续爬取下一个网页,如此往复循环。
不多说,先上我写的一段python脚本,爬取<我们爱讲冷笑话>的随机页面,网址为:http://lengxiaohua.com/random,这个页面每次刷新都有20则不同的随机冷笑话,我的程序功能是:输入数字1到20看对应的笑话,输入new重新爬取另外20则新笑话,输入quit退出程序。代码如下:
#-*- coding:utf-8 -*-
__author__ = '李鹏飞'
import urllib2
import re
class randomJoke:
#初始化方法
def __init__(self):
self.url = 'http://lengxiaohua.com/random'
self.user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
#初始化headers
self.headers = { 'User-Agent' : self.user_agent }
#笑话内容
self.content = []
#获取网页源代码
def getSourceCode(self):
try:
request = urllib2.Request(url = self.url, headers=self.headers)
response = urllib2.urlopen(request)
sourceCode = response.read().decode('utf-8')
return sourceCode
except urllib2.URLError, e:
if hasattr(e,"reason"):
print u"网络错误...",e.reason
return None
#获取笑话
def setContent(self):
sourceCode = self.getSourceCode()
if not sourceCode:
print('获取网页内容失败~!')
quit()
pattern = re.compile(' <pre.*?js="joke_summary".*?"first_char">(.*?)</span>(.*?)</pre>
.*?class="user_info">.*?<a.*?>(.*?)</a>.*?
(.*?)
',re.S)
items = re.findall(pattern,sourceCode)
self.content = items
print u"已经爬取源代码...正在解析源代码..."
#返回笑话
def getContent(self):
return self.content
#打印一则笑话
def printAJoke(self,number):
joke = self.content[number]
print u"作者:%s" %(joke[2])
print u'发表于:'+ joke[3]
#item[0]和item[1]组成完整的内容
print joke[0]+joke[1]
randomJoke = randomJoke()
notQuit = True
print u"你好,这里是随机笑话!"
print u"---------------------"
randomJoke.setContent()
print u"...."
print u"笑话池已经装满,20/20"
print u"输入1到20看笑话~~,输入quit退出,输入new重新爬取新笑话"
while notQuit:
input = raw_input()
if input == "quit" :
print u"bye!"
notQuit = False
elif input == "new":
randomJoke.setContent() #重新抓取笑话内容
print u"...."
print u"笑话池已经装满,20/20"
print u"输入1到20看笑话~~,输入quit退出,输入new重新爬取新笑话"
else:
input = int(input)
randomJoke.printAJoke(input-1)
print u"--------------------------------------------------"
print u"输入1到20看笑话~~,输入quit退出,输入new重新爬取新笑话"
print u"您已经成功退出!"
quit()
保存这段脚本,运行,效果如下:
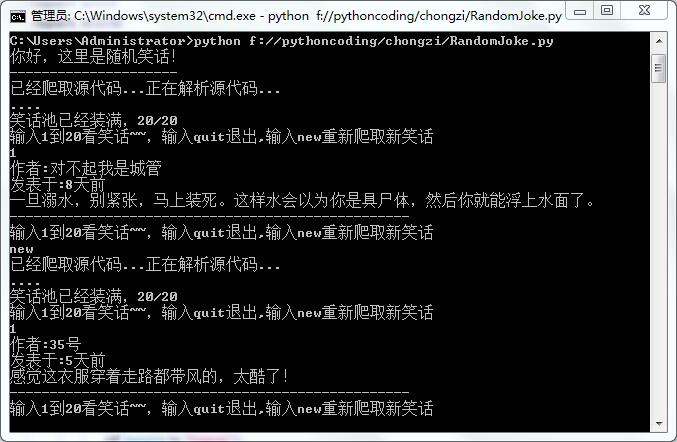
说明一下,有些笑话是带图片的,而我没有抓取图片,仅仅抓取了作者,发表日期,和内容。
下面对程序稍微进行一下解释:
引入了urllib2和re两个模块,urllib2是用来发送http请求的,re是正则表达式的相关模块。
类randomJoke是程序的主要部分,下面就所有的方法,进行简单的说明。
__init__方法
位置:9-15行
这个是初始化方法,定义了四个变量,url为目标网址;user_agent是我们发送http请求的时候伪造的头部的一个客户端信息;headers是头部信息,这里只把user_agent信息加进去就行了;content[]是一个列表,用来存放笑话内容。
getSourceCode方法
位置:18-27行
这个方法是用来获取网页的源代码的。在第20行,发起一个http请求,接着读取返回的源代码,并return源代码。
setContent方法
位置:30-44行
这个方法是比较关键的一个方法,主要是利用正则表达式匹配源代码,并把我们需要的内容爬取下来。第35-41行代码就是正则表达式的匹配模式,我们要抓取网页中的20个笑话,其中的.*?是匹配任意字符,多一个括号,即(.*?)表示匹配的内容是我们需要的内容,在这个片段当中,出现了4个(.*?),因此,程序的第36行,item表示的是一个列表,这个列表的形式是这样的:[[[item1-1],[item1-2],[item1-3],[item1-4]],[…],[…],…[[item20-1],[item20-2],[item20-3],[item20-4]]]。即这个列表有20个元素(代表这个网页的20个笑话),每个元素又是一个列表–列表中有4个元素(代表爬取的4个内容,对应前面说的4个(.*?)。这里附上其中的一小部分网页源代码,对应着网页的html源代码,我们就能感受到这个简单的正则表达式的作用了:
<pre js="joke_summary"><span class="first_char">来</span>表哥家吃饭,小侄子一边看西游记一边手舞足蹈上蹦下跳学猴哥。
我哥:“傻儿子,你是孙悟空吗?”
侄子:“正是,你孙爷爷在此。”
打到现在还在哭。</pre>
</div>
<div class="para_info clearfix">
<div class="user_info">
<img src="http://joke-image.b0.upaiyun.com/img/user/cover/630347-299927_40x40.jpg" class="left corner4px" height="40" width="40"/>
<a href="/user/630347">离愁▍ Feast aw</a>
<p>15天前</p>
一共有20个类似的html片段,正则表达式的作用就是把笑话内容,作者和发表日期提取出来。
printAJoke方法
位置:51-56行
打印一则笑话,在这里我们更能感受到content[]的结构了,因为printAJoke这个方法需要传一个number参数进来,范围是1到20,我们就可以读取对应的笑话了,比如content[0]代表第一则笑话,和java中的数组类似。
53行以后就是程序运行的基本逻辑了,比较简单,就不多解释了。
就这样,一个简单的爬虫就完成了!