代码编写完毕,接下来就是检验代码的效果了。
Storm的代码可以在本地上跑,也可以在集群上跑。为了模拟真实的操作环境,我们当然要在集群上跑,不然前面配置那么多就白配置了。
当然,如果要在本地上跑,拓扑的代码就不一样了,这里先不说,上一篇的代码是按照集群环境来写的。接下来,我们就要验收一下前面的工作成果了。
首先在eclipse的工程中,将代码export成jar文件,步骤很简单,右键–export–jar文件。另外,你得把拓扑的函数完整名字记录下来,就这个例子而言,拓扑类是Topmain,然而完整路径则不一定,在eclipse,直接把鼠标移动到类名上,就能看到完整路径了。如下图:

主类名是stormtest.test.TopMain,这和你的工程、包有关,反正先记录下来。
接下来把3台虚拟机都跑起来。把刚才的jar包上传到第一台服务器上,即配置的主节点。
由于zookeeper我们配置的也是在主节点上,所以在主节点服务器上需要开启zookeeper的服务。切换到zookeeper的主目录下的bin目录,然后运行以下命令
./zkServer.sh start

如上图即运行成功。
然后在这台主机上运行storm的主节点nimbus:将目录切换到storm目录下的bin,运行以下命令:
./storm nimbus 1>/dev/null 2>&1 &
没出错的话,nimbus就会在后台运行了。然后再开启UI,方便我们在线查看工程运行的情况。同样在该目录下,运行以下命令:
./storm ui 1>/dev/null 2>&1 &
输入jps可以查看进程的运行情况:
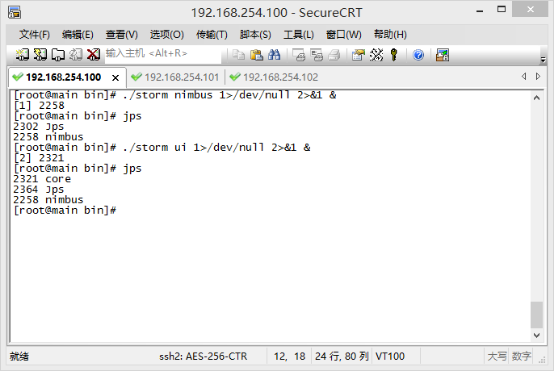
接下来,可以在本地访问UI了,在浏览器输入–主机地址:8080 回车访问。比如我就输入
192.168.254.100:8080,可以看到以下概况:

OK,接下来开启从节点。切换到第二台机器的命令行,同样切换目录到storm下的bin,输入以下命令:
./storm supervisor 1>/dev/null 2>&1 &
如法炮制,切换到第三台机器,同样运行
./storm supervisor 1>/dev/null 2>&1 &
这样,我们的集群就先运行起来了。这时候回去UI刷新一下,可以看到两个从节点确实跑起来了:
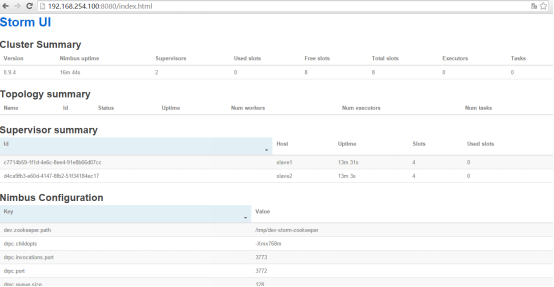
此时此刻,我们要进行最激动人心的一步了,提交拓扑。还记得刚才的jar包吗,我是把它上传到第一台机器的上了 完整路径是/home/filetrans/storm-example.jar
在第一台机器上切换目录到storm下的bin,运行以下命令:
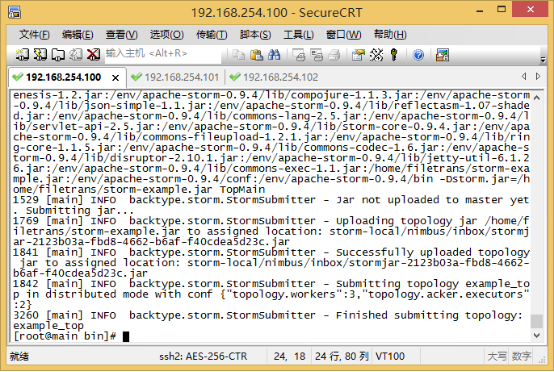
./storm jar /home/filetrans/storm-example.jar stormtest.test.TopMain
以上命令,jar表示运行jar程序,/home/filetrans/storm-example.jar表示jar程序的路径,stormtest.test.TopMain表示主函数的完整路径,这在文章一开始有提到过。
出现以下提示,说明拓扑提交成功了。
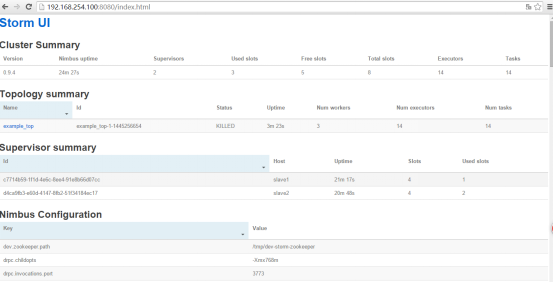
此时再去UI刷新看看,我们会发现有拓扑在工作了,拓扑名为example_top,状态为ACTIVE:
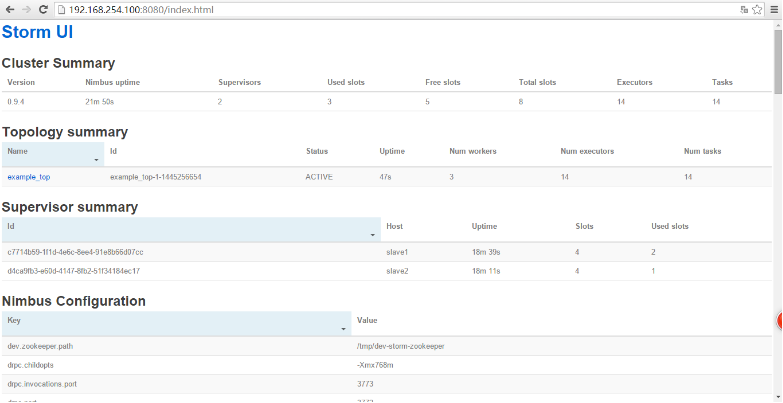
Num Workers是我们代码里设置的worker数,有3个。Num executor为线程数,有14个,14是怎么来的呢?首先以下三行代码,我们可以看出一共有加起来就一共有12个线程了。
//设置spout,并行度为4,第一个参数为自定义的名字
topologyBuilder.setSpout("randomspout", new RandomSpout(),4);
//设置bolt,数据来源是上面的spout
topologyBuilder.setBolt("upperbolt", new UpperBolt(),4).shuffleGrouping("randomspout");
topologyBuilder.setBolt("suffixbolt", new SuffixBolt(), 4).shuffleGrouping("upperbolt");
然后以下这一行代码,有两个线程:
config.setNumAckers(2); //应答器数目
全部加起来,就有14个线程了。
Ok,程序也跑了有一段时间了,我们去看看效果。回头看看SuffixBolt类
我们在里面写了这么一句代码:
fileWriter = new FileWriter("/home/"+UUID.randomUUID());
然后在后面的代码中,往这个文件追加写入了运行结果。
此时我们需要到第二台或者第三台主机上查看这些文件。
切换到/home目录下
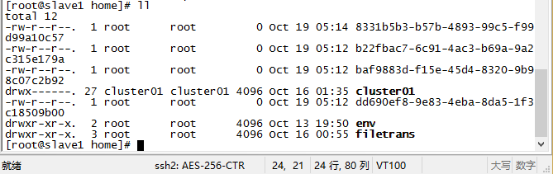
前三个文件就是以随机的uuid明明的记录文件,使用more+文件名命令打开看看。
More 命令一下。

确实有结果,程序跑成功了。
如果这个时候,我们不管程序,它就会继续跑,文件无限增大。所以在项目结束后,需要关闭这个拓扑的工作。
回到主节点上,切换到storm目录下的bin,运行以下命令:
./storm kill example_top
其中的example_top是拓扑名称,是我们在代码里面定义的,在UI上也可以看到。Kill完之后,去UI刷新一下,发现拓扑的状态变为KILLED,再过一会你再刷新,拓扑就直接消失了。
至此,一个完整的程序就跑完了。关于storm,就先告一段落了。