虽然很多情况下,直接对一个url发出请求,就能得到页面的源代码,但是我们还得考虑这么一种情况,就是有的网站为了用户体验,采用了ajax技术–即不刷新页面而改变页面内容,那么我们该怎么获取这些内容呢?
从本质出发,ajax技术也就是这么一个过程:利用js来发起一个post请求–然后接收返回的数据–js改变页面内容。在大多数情况下,我们都是点击一个按钮,然后页面就更新了。从原理上来看,点击某个按钮,就会发送一个post请求(当然还有滚动鼠标发送请求的),服务器再返回结果,再将结果直接更新到页面上。我们的思路是–用爬虫发送同样的post请求,从而获得返回来的数据。
简单点说,对于爬虫而言,在获取数据上,get和post并无太多异样,只是get的话,我们只需要对某个链接发送请求就行,而post,则需要一些表单内容。那么,我们怎么知道该post什么内容过去,又能获得什么响应呢?
以虎嗅网(http://www.huxiu.com/)为例,我用python写了一个爬取它利用ajax更新的数据。
我们打开它的首页,拉到最下面,发现有个“点击加载更多”的按钮,颜色很浅。
点击它,就会有新的内容出现。
我们要做的,就是看看点击这个按钮会发生什么。
我这里以遨游浏览器为例,大多数浏览器(比如chrome,Firefox)应该都有类似的功能,在网页上,点击右键–审查元素,在弹出的窗口菜单栏点击“网络”一栏,在这里,我们可以监控一些get,post等行为。
刚开始是空的。
此时,回到网页上去,点击“点击加载更多”按钮。然后再回到开发者工具那里,会发现,出现了很多的请求:
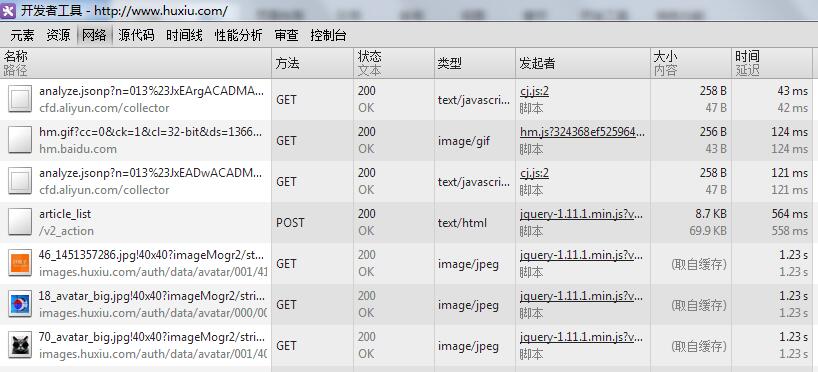
其中,有个请求的方法是POST,这就是我们要找的。点进去,可以看到http报头、预览、响应和cookies。
从中,我们可以获得一些头部信息,以及post的表单数据。
- 头部信息
不同网站对头部信息的要求不同,有的不需要头部信息都能响应,有的则需要头部信息的一部分,虎嗅是不需要头部信息的。
- 表单数据
从开发者工具里面看,虎嗅需要的表单数据有两个,一个是’huxiu_hash_code‘,这个是用来防止csrf的,一个是page,代表页数,我们把huxiu_hash_code复制下来。
构造一个请求过去,会得到一个json格式的响应,内容有msg,total_page,result和data,要的文章数据在data里面。我的程序把data里面的标题都提取出来,打印到屏幕下,下面贴上代码:
#-*- coding:utf-8 -*-
__author__ = '李鹏飞'
import urllib2
import urllib
import json
import re
url = 'http://www.huxiu.com/v2_action/article_list'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
data = {'huxiu_hash_code':'322cf76eec54c4e275d7c8122028a3b2','page':2}
data = urllib.urlencode(data)
try:
request = urllib2.Request(url=url,data=data)
response = urllib2.urlopen(request)
#解析json
result = json.loads(response.read())
print result['msg']
content = result['data']
#匹配文章标题
pattern = re.compile('
<div class="mob-ctt">.*?target="_blank">(.*?)</a>',re.S)
#虎嗅文章标题
items = re.findall(pattern,content)
for item in items:
print item
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
这样子的话,大部分网页就能抓了,管他是post还是get。