WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。
Github上面更新到最新版本2.28,maven的中央仓库暂时只更新到2.09
2.09版本似乎没有把ContentExtractor集成进来,所以还是建议直接在github上先下载最新版本的jar,然后在buildpath里面引进来就行。
项目介绍:http://crawlscript.github.io/WebCollector/
项目github:https://github.com/CrawlScript/WebCollector
中文文档:https://github.com/CrawlScript/WebCollector/blob/master/README.zh-cn.md
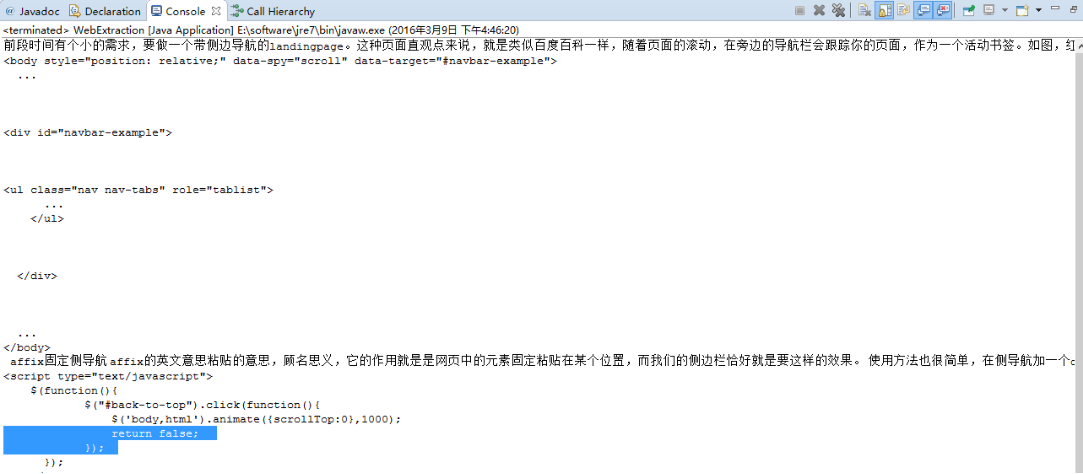
来个简单的例子,对于中文url的支持,这个框架还是可以的。
import cn.edu.hfut.dmic.contentextractor.ContentExtractor;
import cn.edu.hfut.dmic.contentextractor.News;
public class WebExtraction {
public static void main (String args[]) throws Exception{
String url = "https://www.lookfor404.com/利用bootstrap的滚动监听+affix做一个侧导航landingpage/";
String content = ContentExtractor.getContentByUrl(url);
System.out.println("content:"+content);
News news = ContentExtractor.getNewsByUrl(url);
System.out.println("title:"+news.getTitle());
System.out.println("content:"+news.getContent());
}
}
输出结果如下: