配置完hadoop的环境,照例,肯定要跑一个简单的程序测试一下。
似乎提到hadoop,就不得不提mapreduce,作为mapreduce的一个开源实现,hadoop的应用非常广。引用一段文字,大概就能了解一下它们的历史了:
2003年和2004年,Google公司在国际会议上分别发表了两篇关于Google分布式文件系统和MapReduce的论文,公布了Google的GFS和MapReduce的基本原理和主要设计思想。2004年,开源项目Lucene(搜索索引程序库)和Nutch(搜索引擎)的创始人Doug Cutting发现MapReduce正是其所需要的解决大规模Web数据处理的重要技术,因而模仿Google MapReduce,基于Java设计开发了一个称为Hadoop的开源MapReduce并行计算框架和系统。自此,Hadoop成为Apache开源组织下最重要的项目,自其推出后很快得到了全球学术界和工业界的普遍关注,并得到推广和普及应用。
废话不多说,我们来看看怎么跑基于mapreduce的简单例子–wordcount。
首先要格式化namenode。根据你的目录,运行以下的命令
hadoop/bin/hadoop namenode -format
查看信息的倒数几行,如果显示:
Storage directory ~/hadoop-2.5.2/hdfs/name has been successfully formatted
则说明成功了!
接下来启动hdfs,在hadoop文件夹下的sbin文件夹内运行以下命令(根据你当前目录的位置自行调整):
sbin/start-dfs.sh
在主节点运行jps命令,看到namenode进程已经启动:
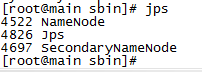
在子节点键入jps命令,看到datanode进程已经启动:
![]()
因为之前的配置,所以我们可以在50070端口查看hadoop的工作状态。
比如我可以在浏览器输入:http://192.168.254.100:50070/ (根据你的主节点ip改变网址),可以看到工作状态:
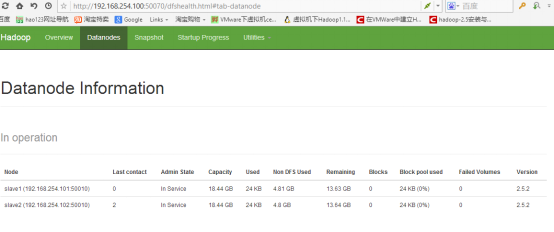
接下来启动yarn,在sbin目录下:
sbin/start-yarn.sh
好了,准备工作完成,接下来,跑程序。
1.在hdfs上创建input目录
如果你的hadoop已经加入环境变量了,你就不需要切换目录到bin下,直接hadoop + 命令就可以了。否则,你得先切换到hadoop的bin目录下,运行以下命令
./hadoop fs -mkdir -p input
2.新建文本
新建一个test.txt
vim /home/test.txt
在里面输入任意内容,单词,然后保存。比如我是这样输入的:

将文件复制到hdfs的input目录下:
./hadoop fs -put /home/test.txt input
3.运行wordcount程序
程序在hadoop文件夹下的share下,注意以下命令的路径:
./Hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.5.2-sources.jar org.apache.hadoop.examples.WordCount input output
4.观察结果
这是运行过程中的状态:
看看结果生成了什么文件:
./hadoop fs -ls output/
结果生成了两个文件:

part-r -00000就是我们要的结果。
看看里面的内容:
./hadoop fs -cat output/part-r-00000
里面是计数结果:

以上就是wordcount运行的全过程,最后退出hdfs和yarn。先切换到sbin目录下,然后运行以下命令即可:
./stop-dfs.sh ./stop-yarn.sh