在上一节《centos+虚拟机配置hadoop2.5.2-前期准备》,讲了一下配置hadoop的前期工作,方便我们之后的操作。做好前期的准备工作之后,可以进行hadoop的安装配置了。
本文配置的hadoop版本为2.5.2,可以到这里下载:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.5.2/ 我下载的是tar.gz格式的。
下载完成,上传到centos服务器(虚拟机里的centos)。首先解压,我把它解压到
这个目录下:/env/
tar -zvxf hadoop-2.5.2.tar.gz -C /env/
随后要设置环境变量。把这些命令写入/etc/profile和~/.bashrc 中,说个题外话,通常我们配置环境变量都会接触到这两个文件,他们到底有什么区别呢?找了找资料:
bashrc与profile都用于保存用户的环境信息,bashrc用于交互式non-loginshell,而profile用于交互式login shell
先编辑/etc/profile
vi /etc/profile
在文本的末尾加入以下命令,具体的路径以你自己配置的为准:
export HADOOP_PREFIX=/env/hadoop-2.5.2 export YARN_CONF_DIR=/env/hadoop-2.5.2 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_PREFIX/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib" export HADOOP_HOME=/env/hadoop-2.5.2 export HADOOP_HOME_WARN_SUPPRESS=1
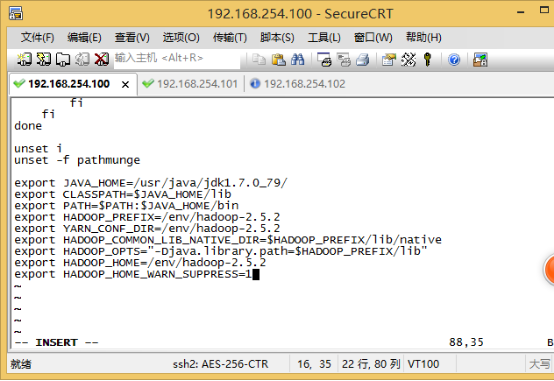
使配置生效:
source /etc/profile
再编辑~/.bashrc
vi ~/.bashrc
加入以下内容,具体路径仍以你的配置为准:
export JAVA_HOME=/usr/java/jdk1.7.0_79 export JRE_HOME=/usr/java/jdk1.7.0_79/jre export HADOOP_HOME=/env/hadoop-2.5.2 export HADOOP_DEV_HOME=/env/hadoop-2.5.2 export HADOOP_COMMON_HOME=/env/hadoop-2.5.2 export HADOOP_HDFS_HOME=/env/hadoop-2.5.2 export HADOOP_CONF_DIR=/env/hadoop-2.5.2/conf
使配置生效:
source ~/.bashrc
然后在另外两台主机上重复以上步骤,将环境变量配置好。
接下来,来配置一下hadoop。切换目录
cd /env/hadoop-2.5.2/etc/hadoop/
要配置5个文件:core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml和slaves
首先编辑core-site.xml,在configuration里面添加以下内容
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://main:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/env/hadoop-2.5.2/tmp</value>
</property>
</configuration>
随后编辑vim hdfs-site.xml,配置hadoop的文件系统hdfs。在configuration里面添加以下内容
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property> <property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
编辑yarn-site.xml,这个是map-reduce的新框架yarn的配置文件。添加以下内容,里面的value,可以设置主机名,也可以设置为ip:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.254.100:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.254.100:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.254.100:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.254.100:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.254.100:8088</value>
</property>
</configuration>
然后编辑mapred-site.xml,这个是map-reduce任务页面的配置,添加以下内容:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>main:9001</value>
</property>
</configuration>
最后,还是在刚才的目录下,编辑slaves文件,将两个子节点的ip或者主机名添加进去
vi slaves
编辑内容如下:
#localhost 192.168.254.101 192.168.254.102
保存,搞定!
将配置好的hadoop直接复制到另外两台主机(-r参数是复制文件夹,不要漏掉):
scp -r /env/hadoop-2.5.2 root@slave1:/env/ scp -r /env/hadoop-2.5.2 root@slave2:/env/
至此,配置完毕,下一篇还是老样子,跑一个简单的程序。