上一篇写了MapReduce的经典例子–WordCount,为了进一步理解和熟悉一下MapReduce这个框架,这次再来看看官方给出的另外一个例子:WordMean
WordMean,Mean我们都知道,是平均数的意思。所以很显然,这个程序是用来统计单词的平均字符数的。
先来跑一下。
在《centos+虚拟机配置hadoop2.5.2-mapreduce-wordcount例子》里面,我已经在hdfs里面新建了一个input文件夹,并且在里面放置了一个test.txt,内容如下:

事实上,无论是WordCount还是WordMean,都不仅仅是只处理一个文件,为了验证这一点,我在跑WordMean之前,建多一个文件。
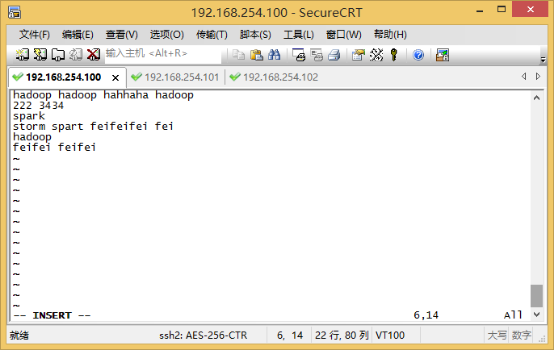
先在linux下新建一个test2.txt
vim /home/txt/test2.txt
内容如下:
将其复制到hdfs下的input文件夹内:
hadoop fs -put /home/txt/text2.txt input
准备工作完毕,现在跑一下程序。仍然是这个jar文件:/hadoop/share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.5.2-sources.jar
输出我们放在名为wordmean-output的文件夹下(命令行的最后一个参数),具体运行命令如下:
hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.5.2-sources.jar org.apache.hadoop.examples.WordMean input wordmean-output
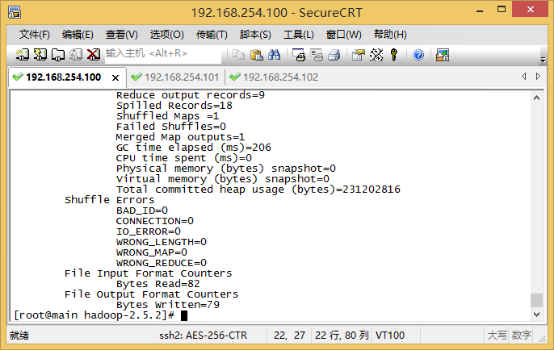
运行过程中,控制台最后几行信息输出如下:
Bytes Read=173
File Output Format Counters
Bytes Written=20
The mean is: 5.653846153846154
最后一行显示,the mean is 5.653846153846154,即单词的平均字符数。
我手工统计了一下,一共有26个单词,合计147个字符,147/26,确实是这个数。为了进一步确认,到wordmean-output那里看一下输出结果。
hadoop fs -cat wordmean-output/part-r-00000
结果如下,看来我手工也没数错哈哈:

跑完程序了,把源代码贴一下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import com.google.common.base.Charsets;
public class WordMean extends Configured implements Tool {
private double mean = 0;
private final static Text COUNT = new Text("count");
private final static Text LENGTH = new Text("length");
private final static LongWritable ONE = new LongWritable(1);
public static class WordMeanMapper extends
Mapper<Object, Text, Text, LongWritable> {
private LongWritable wordLen = new LongWritable();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
String string = itr.nextToken();
this.wordLen.set(string.length());
context.write(LENGTH, this.wordLen);
context.write(COUNT, ONE);
}
}
}
public static class WordMeanReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable sum = new LongWritable();
public void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
int theSum = 0;
for (LongWritable val : values) {
theSum += val.get();
}
sum.set(theSum);
context.write(key, sum);
}
}
private double readAndCalcMean(Path path, Configuration conf)
throws IOException {
FileSystem fs = FileSystem.get(conf);
Path file = new Path(path, "part-r-00000");
if (!fs.exists(file))
throw new IOException("Output not found!");
BufferedReader br = null;
// average = total sum / number of elements;
try {
br = new BufferedReader(new InputStreamReader(fs.open(file), Charsets.UTF_8));
long count = 0;
long length = 0;
String line;
while ((line = br.readLine()) != null) {
StringTokenizer st = new StringTokenizer(line);
// grab type
String type = st.nextToken();
// differentiate
if (type.equals(COUNT.toString())) {
String countLit = st.nextToken();
count = Long.parseLong(countLit);
} else if (type.equals(LENGTH.toString())) {
String lengthLit = st.nextToken();
length = Long.parseLong(lengthLit);
}
}
double theMean = (((double) length) / ((double) count));
System.out.println("The mean is: " + theMean);
return theMean;
} finally {
if (br != null) {
br.close();
}
}
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(), new WordMean(), args);
}
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: wordmean <in> <out>");
return 0;
}
Configuration conf = getConf();
@SuppressWarnings("deprecation")
Job job = new Job(conf, "word mean");
job.setJarByClass(WordMean.class);
job.setMapperClass(WordMeanMapper.class);
job.setCombinerClass(WordMeanReducer.class);
job.setReducerClass(WordMeanReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
Path outputpath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outputpath);
boolean result = job.waitForCompletion(true);
mean = readAndCalcMean(outputpath, conf);
return (result ? 0 : 1);
}
/**
* Only valuable after run() called.
*
* @return Returns the mean value.
*/
public double getMean() {
return mean;
}
}
简单分析一下,大概的过程如下:
map过程
看第43和44行,可以知道map输出了两个键值对,一个是<“length”,单词的长度>,一个是<“count”,1>即单词的个数。
reduce过程
代码56至66行。对已经处理好的键值对进行最终处理,分别处理<“length”,<单词的长度>>,和<“count”,<1,1,1,1,1…>>,做的是同样的处理–累加。
readAndCalcMean方法
第68行到111行,主要是读取输出的文件,计算平均数。如上文所示,文件里面的内容如下:
所以这个方法,就是用来读取26和147两个数字,作除法,然后输出到屏幕。具体代码写的很清楚,就不细读了。