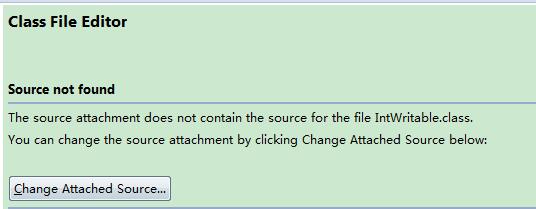
之前在做文本挖掘实验的时候,千辛万苦要到这份duc2002的语料库之后,就要对它进行处理了,它是存在xml文件里的。
一直在用java进行相关的处理,所以这次也不例外,java中,关于xml文件解析的框架有很多,在网上也看了很多,最终选择了dom4j这个框架。下面就简单记录一下使用的过程。
首先去下载,我下载的是dom4j1.6.1。下载地址:http://sourceforge.net/projects/dom4j/files/
下载之后解压就行。然后在工程的buildpath里面添加一个external jars,选择刚才解压之后根目录下的dom4j-1.6.1.jar文件。
我的这个xml文件的层级比较多,对照我要需要的内容,这里就列举一下一部分的内容:
<corpus>
<cluster cid="d061j">
<title>d061j</title>
<topics>
<topic>d061j</topic>
</topics>
<queries/>
<documents>
<document docid="AP880911-0016">
<title> Hurricane Gilbert Heads Toward Dominican Coast</title>
<text>
<s sid="9"> Hurricane Gilbert swept toward the Dominican Republic Sunday, and the Civil Defense alerted its heavily populated south coast to prepare for high winds, heavy rains and high seas.</s>
<s sid="10"> The storm was approaching from the southeast with sustained winds of 75 mph gusting to 92 mph.</s>
<s sid="11"> ``There is no need for alarm,'' Civil Defense Director Eugenio Cabral said in a television alert shortly before midnight Saturday.</s>
<s sid="12"> Cabral said residents of the province of Barahona should closely follow Gilbert's movement.</s>
<s sid="13"> An estimated 100,000 people live in the province, including 70,000 in the city of Barahona, about 125 miles west of Santo Domingo.</s>
<s sid="14"> Tropical Storm Gilbert formed in the eastern Caribbean and strengthened into a hurricane Saturday night.</s>
<s sid="15"> The National Hurricane Center in Miami reported its position at 2 a.m. Sunday at latitude 16.1 north, longitude 67.5 west, about 140 miles south of Ponce, Puerto Rico, and 200 miles southeast of Santo Domingo.</s>
<s sid="16"> The National Weather Service in San Juan, Puerto Rico, said Gilbert was moving westward at 15 mph with a ``broad area of cloudiness and heavy weather'' rotating around the center of the storm.</s>
<s sid="17"> The weather service issued a flash flood watch for Puerto Rico and the Virgin Islands until at least 6 p.m. Sunday.</s>
<s sid="18"> Strong winds associated with the Gilbert brought coastal flooding, strong southeast winds and up to 12 feet feet to Puerto Rico's south coast.</s>
<s sid="19"> There were no reports of casualties.</s>
<s sid="20"> San Juan, on the north coast, had heavy rains and gusts Saturday, but they subsided during the night.</s>
<s sid="21"> On Saturday, Hurricane Florence was downgraded to a tropical storm and its remnants pushed inland from the U.S. Gulf Coast.</s>
<s sid="22"> Residents returned home, happy to find little damage from 80 mph winds and sheets of rain.</s>
<s sid="23"> Florence, the sixth named storm of the 1988 Atlantic storm season, was the second hurricane.</s>
<s sid="24"> The first, Debby, reached minimal hurricane strength briefly before hitting the Mexican coast last month .</s>
</text>
</document>
</documents>
</cluster>
</corpus>
每个cluster有自己的title,接下来,documents是和cluster同级的,ducuments里面又有若干document,每个document下有title,text,text下有p标签,p标签下又有各个句子,标签是s。
我的任务是,将每一篇document的内容输出到一个文本文件,命名格式为:”cl”+cid+”-“+”docid”+docid,其中cid和docid分别是cluster和document的一个属性。
PS:我把文本文件duc2002.xml已经复制到本项目的scr下了。
下面贴上源代码:
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.util.Iterator;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class MyTest {
public static void main(String[] args) throws Exception {
SAXReader reader = new SAXReader();
Document thedocument = reader.read(new File("./src/duc2002.xml"));
Element root = thedocument.getRootElement();
System.out.println(root);
Iterator it = root.elementIterator();
int count = 0;
for (Iterator i = root.elementIterator("cluster"); i.hasNext();) {
Element cluster = (Element) i.next();
System.out.println("cluster id:"
+ cluster.attribute("cid").getText()); // cluster的id
Element documents = cluster.element("documents");
for (Iterator j = documents.elementIterator("document"); j
.hasNext();) {
Element document = (Element) j.next();
Element title = document.element("title");
for (Iterator k = document.element("models").elementIterator(
"model"); k.hasNext();) {
Element model = (Element) k.next();
}
File file = new File("F:\\xmltest\\" + "cl"
+ cluster.attribute("cid").getText() + "-" + "docid"
+ document.attribute("docid").getText() + ".txt");
file.createNewFile();
BufferedWriter bw = new BufferedWriter(new FileWriter(file,
true));
bw.write("title:" + title.getText());
bw.newLine();
for (Iterator l = document.element("text").element("p")
.elementIterator("s"); l.hasNext();) {
Element sentence = (Element) l.next();
bw.write(sentence.getText().trim());
bw.newLine();
}
bw.close();
}
count++;
System.out.println(count + "finished!");
}
}
}
这段程序在F盘的xmltest文件夹下不断生成文本文件,我就拿列举的那部分内容生成的文本文件做例子,输出结果是这样的:
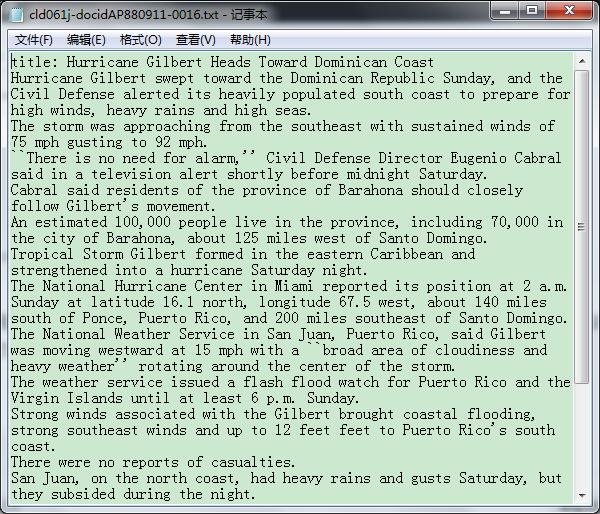
对照程序,再简单整理一下dom4j基本的xml解析功能:
- 第13-15行,初始化解析器,读入xml文件,获得根节点
- 第19行,用
root.elementIterator("cluster")来迭代获得root节点下的cluster
- 第20行,用
Element cluster = (Element) i.next();来获得每一个cluster,如果要获得属性,比如xml文件第2行的cid,可以用第22行的cluster.attribute("cid").getText());
- 用element方法获得子节点,如23行的
Element documents = cluster.element("documents");
- 获得节点的内容,直接用getText()方法,如第38行,获得<title>的内容