俞鸿魁, 张华平, 刘群. 基于角色标注的中文机构名识别[C]// Advances in Computation of Oriental Languages–Proceedings of the, International Conference on Computer Processing of Oriental Languages. 2003.
def forward_prop_step(x_t, s_t1_prev):
# This is how we calculated the hidden state in a simple RNN. No longer!
# s_t = T.tanh(U[:,x_t] + W.dot(s_t1_prev))
# Get the word vector
x_e = E[:,x_t]
# GRU Layer
z_t1 = T.nnet.hard_sigmoid(U[0].dot(x_e) + W[0].dot(s_t1_prev) + b[0])
r_t1 = T.nnet.hard_sigmoid(U[1].dot(x_e) + W[1].dot(s_t1_prev) + b[1])
c_t1 = T.tanh(U[2].dot(x_e) + W[2].dot(s_t1_prev * r_t1) + b[2])
s_t1 = (T.ones_like(z_t1) - z_t1) * c_t1 + z_t1 * s_t1_prev
# Final output calculation
# Theano's softmax returns a matrix with one row, we only need the row
o_t = T.nnet.softmax(V.dot(s_t1) + c)[0]
return [o_t, s_t1]
举个例子。有一个句子“He went to buy some chocolate”,这个句子是怎么生成的呢?我们可以将其看作给定了”He”这个条件之后出现”went”的概率,乘以给定了”He went”这个条件之后出现”to”的概率,乘以…(以此类推)给定了”He went to buy some”这个条件之后出现”chocolate”的概率。
在代码里面vocabulary_size代表着词汇表的规模(我将词汇表的大小设置为8000,代表着8000个最常出现的单词,当然你也可以更改啦)。对于词汇表里没有的单词,我们将它设置为UNKNOWN_TOKEN。举个例子,如果我们的词汇表里面没有nonlinearities这个单词,那么句子“nonlineraties are important in neural networks”就会被表示成“UNKNOWN_TOKEN are important in Neural Networks”,UNKNOWN_TOKEN这个词也是在词汇表里面的。最后,当我们需要预测单词的时候,如果预测出来的单词是UNKNOWN_TOKEN的话,我们可以用选择词汇表之外的任意一个单词来替代它,又或者,干脆我们就不要生成含有UNKNOWN_TOKEN的文本。
循环神经网络RNN的输入都是向量,而不是我们数据集里面的字符串,所以我们需要将数据集的字符串映射成向量。在代码里,用的是这两个方法:index_to_word和word_to_index,单词和索引之间可以相互映射。比如,”how”,”are”,”you”这3个词可能处于词汇表的第4,100,7733个位置,那么一个训练输入句子“how are you“就会被表达成[0,4,100,7733],其中的0是上面提到的开始标记SENTENCE_START的位置。由于我们是为了训练语言模型,那么对应的输出应该是每个单词往后移动一个位置,对应为[4,100,7733,1],其中的1是上面提到的结束标记SENTENCE_END。下面是实现的代码片段:
vocabulary_size = 8000
unknown_token = "UNKNOWN_TOKEN"
sentence_start_token = "SENTENCE_START"
sentence_end_token = "SENTENCE_END"
# Read the data and append SENTENCE_START and SENTENCE_END tokens
print "Reading CSV file..."
with open('data/reddit-comments-2015-08.csv', 'rb') as f:
reader = csv.reader(f, skipinitialspace=True)
reader.next()
# Split full comments into sentences
sentences = itertools.chain(*[nltk.sent_tokenize(x[0].decode('utf-8').lower()) for x in reader])
# Append SENTENCE_START and SENTENCE_END
sentences = ["%s %s %s" % (sentence_start_token, x, sentence_end_token) for x in sentences]
print "Parsed %d sentences." % (len(sentences))
# Tokenize the sentences into words
tokenized_sentences = [nltk.word_tokenize(sent) for sent in sentences]
# Count the word frequencies
word_freq = nltk.FreqDist(itertools.chain(*tokenized_sentences))
print "Found %d unique words tokens." % len(word_freq.items())
# Get the most common words and build index_to_word and word_to_index vectors
vocab = word_freq.most_common(vocabulary_size-1)
index_to_word = [x[0] for x in vocab]
index_to_word.append(unknown_token)
word_to_index = dict([(w,i) for i,w in enumerate(index_to_word)])
print "Using vocabulary size %d." % vocabulary_size
print "The least frequent word in our vocabulary is '%s' and appeared %d times." % (vocab[-1][0], vocab[-1][1])
# Replace all words not in our vocabulary with the unknown token
for i, sent in enumerate(tokenized_sentences):
tokenized_sentences[i] = [w if w in word_to_index else unknown_token for w in sent]
print "\nExample sentence: '%s'" % sentences[0]
print "\nExample sentence after Pre-processing: '%s'" % tokenized_sentences[0]
# Create the training data
X_train = np.asarray([[word_to_index[w] for w in sent[:-1]] for sent in tokenized_sentences])
y_train = np.asarray([[word_to_index[w] for w in sent[1:]] for sent in tokenized_sentences])
给个输入和输出的具体例子:
x:
SENTENCE_START what are n’t you understanding about this ? !
[0, 51, 27, 16, 10, 856, 53, 25, 34, 69]
y:
what are n’t you understanding about this ? ! SENTENCE_END
[51, 27, 16, 10, 856, 53, 25, 34, 69, 1]
def forward_propagation(self, x):
# The total number of time steps
T = len(x)
# During forward propagation we save all hidden states in s because need them later.
# We add one additional element for the initial hidden, which we set to 0
s = np.zeros((T + 1, self.hidden_dim))
s[-1] = np.zeros(self.hidden_dim)
# The outputs at each time step. Again, we save them for later.
o = np.zeros((T, self.word_dim))
# For each time step...
for t in np.arange(T):
# Note that we are indxing U by x[t]. This is the same as multiplying U with a one-hot vector.
s[t] = np.tanh(self.U[:,x[t]] + self.W.dot(s[t-1]))
o[t] = softmax(self.V.dot(s[t]))
return [o, s]
def predict(self, x):
# Perform forward propagation and return index of the highest score
o, s = self.forward_propagation(x)
return np.argmax(o, axis=1)
让我们来试运行一下
np.random.seed(10)
model = RNNNumpy(vocabulary_size)
o, s = model.forward_propagation(X_train[10])
print o.shape
print o
def calculate_total_loss(self, x, y):
L = 0
# For each sentence...
for i in np.arange(len(y)):
o, s = self.forward_propagation(x[i])
# We only care about our prediction of the "correct" words
correct_word_predictions = o[np.arange(len(y[i])), y[i]]
# Add to the loss based on how off we were
L += -1 * np.sum(np.log(correct_word_predictions))
return L
def calculate_loss(self, x, y):
# Divide the total loss by the number of training examples
N = np.sum((len(y_i) for y_i in y))
return self.calculate_total_loss(x,y)/N
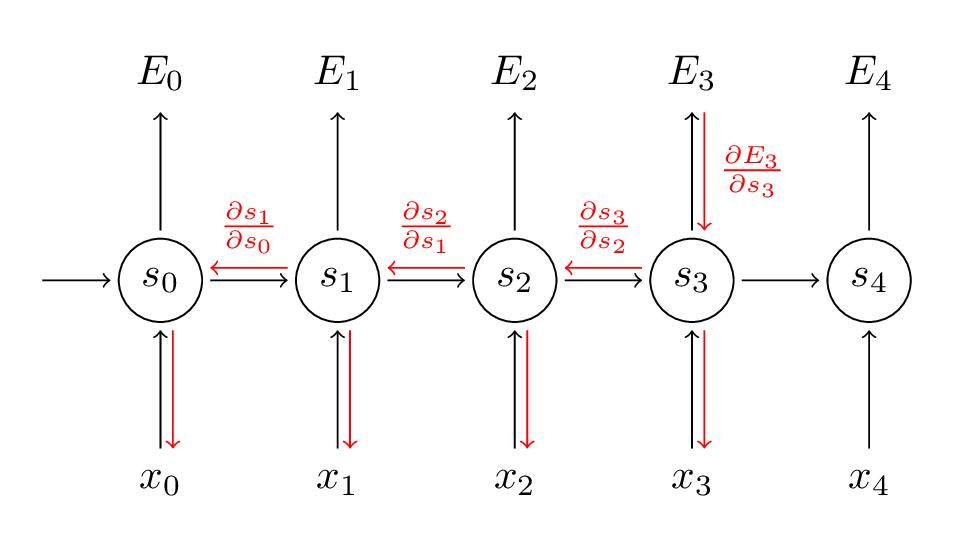
再回到我们的问题上来,我们该如何计算上面所提到的梯度呢?在传统的神经网络中,我们使用的是反向传播算法,而在RNN中,我们使用BPTT(Backpropagation Through Time)算法,用中文直白的理解就是,跨越时间的反向传播算法。为什么在RNN里面就不一样了呢?因为在这个模型当中,所有时间步的参数是共享权重的,而每一个输出的梯度,不仅仅取决于当前时间步的计算结果,还取决于在此之前所有时间步的计算结果。当然了,我们解决这个问题也是使用链式法则。关于反向传播算法,可以参看我之前写的【从梯度下降到反向传播(附计算例子)】,也可以参看这两篇英文博客:
def gradient_check(self, x, y, h=0.001, error_threshold=0.01):
# Calculate the gradients using backpropagation. We want to checker if these are correct.
bptt_gradients = self.bptt(x, y)
# List of all parameters we want to check.
model_parameters = ['U', 'V', 'W']
# Gradient check for each parameter
for pidx, pname in enumerate(model_parameters):
# Get the actual parameter value from the mode, e.g. model.W
parameter = operator.attrgetter(pname)(self)
print "Performing gradient check for parameter %s with size %d." % (pname, np.prod(parameter.shape))
# Iterate over each element of the parameter matrix, e.g. (0,0), (0,1), ...
it = np.nditer(parameter, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
ix = it.multi_index
# Save the original value so we can reset it later
original_value = parameter[ix]
# Estimate the gradient using (f(x+h) - f(x-h))/(2*h)
parameter[ix] = original_value + h
gradplus = self.calculate_total_loss([x],[y])
parameter[ix] = original_value - h
gradminus = self.calculate_total_loss([x],[y])
estimated_gradient = (gradplus - gradminus)/(2*h)
# Reset parameter to original value
parameter[ix] = original_value
# The gradient for this parameter calculated using backpropagation
backprop_gradient = bptt_gradients[pidx][ix]
# calculate The relative error: (|x - y|/(|x| + |y|))
relative_error = np.abs(backprop_gradient - estimated_gradient)/(np.abs(backprop_gradient) + np.abs(estimated_gradient))
# If the error is to large fail the gradient check
if relative_error > error_threshold:
print "Gradient Check ERROR: parameter=%s ix=%s" % (pname, ix)
print "+h Loss: %f" % gradplus
print "-h Loss: %f" % gradminus
print "Estimated_gradient: %f" % estimated_gradient
print "Backpropagation gradient: %f" % backprop_gradient
print "Relative Error: %f" % relative_error
return
it.iternext()
print "Gradient check for parameter %s passed." % (pname)
# Performs one step of SGD.
def numpy_sdg_step(self, x, y, learning_rate):
# Calculate the gradients
dLdU, dLdV, dLdW = self.bptt(x, y)
# Change parameters according to gradients and learning rate
self.U -= learning_rate * dLdU
self.V -= learning_rate * dLdV
self.W -= learning_rate * dLdW
RNNNumpy.sgd_step = numpy_sdg_step
# Outer SGD Loop
# - model: The RNN model instance
# - X_train: The training data set
# - y_train: The training data labels
# - learning_rate: Initial learning rate for SGD
# - nepoch: Number of times to iterate through the complete dataset
# - evaluate_loss_after: Evaluate the loss after this many epochs
def train_with_sgd(model, X_train, y_train, learning_rate=0.005, nepoch=100, evaluate_loss_after=5):
# We keep track of the losses so we can plot them later
losses = []
num_examples_seen = 0
for epoch in range(nepoch):
# Optionally evaluate the loss
if (epoch % evaluate_loss_after == 0):
loss = model.calculate_loss(X_train, y_train)
losses.append((num_examples_seen, loss))
time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print "%s: Loss after num_examples_seen=%d epoch=%d: %f" % (time, num_examples_seen, epoch, loss)
# Adjust the learning rate if loss increases
if (len(losses) > 1 and losses[-1][1] > losses[-2][1]):
learning_rate = learning_rate * 0.5
print "Setting learning rate to %f" % learning_rate
sys.stdout.flush()
# For each training example...
for i in range(len(y_train)):
# One SGD step
model.sgd_step(X_train[i], y_train[i], learning_rate)
num_examples_seen += 1
def generate_sentence(model):
# We start the sentence with the start token
new_sentence = [word_to_index[sentence_start_token]]
# Repeat until we get an end token
while not new_sentence[-1] == word_to_index[sentence_end_token]:
next_word_probs = model.forward_propagation(new_sentence)
sampled_word = word_to_index[unknown_token]
# We don't want to sample unknown words
while sampled_word == word_to_index[unknown_token]:
samples = np.random.multinomial(1, next_word_probs[-1])
sampled_word = np.argmax(samples)
new_sentence.append(sampled_word)
sentence_str = [index_to_word[x] for x in new_sentence[1:-1]]
return sentence_str
num_sentences = 10
senten_min_length = 7
for i in range(num_sentences):
sent = []
# We want long sentences, not sentences with one or two words
while len(sent) < senten_min_length:
sent = generate_sentence(model)
print " ".join(sent)
下面是我挑选的几个生成的句子(我人工为首字母加上了大写)
Anyway, to the city scene you’re an idiot teenager.
What ? ! ! ! ! ignore!
Screw fitness, you’re saying: https
Thanks for the advice to keep my thoughts around girls.
Yep, please disappear with the terrible generation.
RNN模型的训练过程和传统神经网络训练过程是类似的,我们同样的使用反向传播算法,当然了,具体的过程会有点不同,因为在RNN中,横向展开的每一层都是共享权重的,每一个输出的梯度(gradient)不仅仅依赖于当下这个时间点,还依赖于过去的时间点。举个例子,想要计算时间点t=4的梯度,我们需要反向传播3个时间点,并把梯度相加。这个算法就叫做BPTT(Backpropagation Through Time),后面会介绍。现在只需要知道,BPTT算法本身是有局限性的,它不能长期记忆,还会引起梯度消失和梯度爆炸问题,LSTM就是用来解决这个问题的,后面也会介绍LSTM。
 来表示,用来捕获词本身的信息。这个词向量由两部分concat起来,一部分是用GloVe训练出来的词向量
来表示,用来捕获词本身的信息。这个词向量由两部分concat起来,一部分是用GloVe训练出来的词向量 ,另一部分,是字符级别的向量
,另一部分,是字符级别的向量 。
。
![w = [c_1, \ldots, c_p]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-7559e0898757e14cc865bbe19d8b827a_l3.png "Rendered by QuickLaTeX.com") 里面的每一个字母(区分大小写),我们用
里面的每一个字母(区分大小写),我们用 这个向量来表示,对字母级别的embedding跑一个bi-LSTM,然后将最后的隐状态输出拼接起来(因为是双向,所以有两个最后隐状态,如上图),得到一个固定长度的表达
这个向量来表示,对字母级别的embedding跑一个bi-LSTM,然后将最后的隐状态输出拼接起来(因为是双向,所以有两个最后隐状态,如上图),得到一个固定长度的表达 和Glove训练好的w_{glove}拼接起来,得到某个词最终的词向量表达:
和Glove训练好的w_{glove}拼接起来,得到某个词最终的词向量表达:![w = [w_{glove}, w_{chars}] \in \mathbb{R}^n](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-fa9315d0afaa848d010d81a171f2bf0a_l3.png "Rendered by QuickLaTeX.com") ,其中
,其中 。
。 之后,就可以对一个句子里的每一个词跑LSTM或者双向LSTM了,然后得到另一个向量表示:
之后,就可以对一个句子里的每一个词跑LSTM或者双向LSTM了,然后得到另一个向量表示: ,如下图:
,如下图:
 ,得到m个输出:
,得到m个输出: 。现在的输出,是包含上下文信息的:
。现在的输出,是包含上下文信息的: 和偏置矩阵
和偏置矩阵 ,最后计算某个词的得分向量
,最后计算某个词的得分向量 ,
,![s[i]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-32cb48f81effa33197a00874d2826041_l3.png "Rendered by QuickLaTeX.com") 可以解释为,某个词标记成第
可以解释为,某个词标记成第 个tag的得分,tensorflow的实现是这样的:
个tag的得分,tensorflow的实现是这样的: ,一系列的得分向量
,一系列的得分向量 ,还有一系列标签
,还有一系列标签 ,线性CRF的计算公式是这样的:
,线性CRF的计算公式是这样的:![\[\begin{aligned}C(y_1, \ldots, y_m) &= b[y_1] &+ \sum_{t=1}^{m} s_t [y_t] &+ \sum_{t=1}^{m-1} T[y_{t}, y_{t+1}] &+ e[y_m]\\&= \text{begin} &+ \text{scores} &+ \text{transitions} &+ \text{end}\end{aligned}\]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-d0fb542ccdf36647a4f115d378d8c306_l3.png "Rendered by QuickLaTeX.com")
 是转移矩阵,尺寸为
是转移矩阵,尺寸为 ,用来刻画相邻tag的依赖、转移关系;
,用来刻画相邻tag的依赖、转移关系; 是结束、开始tag的代价向量。下面是一个计算例子:
是结束、开始tag的代价向量。下面是一个计算例子:
 种可能,代价太大了。
种可能,代价太大了。 是时间步
是时间步 的解(每个时间步都是有9种可能的),那么,继续往前推,时间步
的解(每个时间步都是有9种可能的),那么,继续往前推,时间步 的解,可以由下式表示:
的解,可以由下式表示:![\[\begin{aligned}\tilde{s}_t(y_t) &= \operatorname{argmax}_{y_t, \ldots, y_m} C(y_t, \ldots, y_m)\\&= \operatorname{argmax}_{y_{t+1}} s_t [y_t] + T[y_{t}, y_{t+1}] + \tilde{s}_{t+1}(y^{t+1})\end{aligned}\]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-c13eb6c5b30757b2ccbe503a9ab1e609_l3.png "Rendered by QuickLaTeX.com")
 ,由于我们进行了
,由于我们进行了 步,所以总的复杂度是
步,所以总的复杂度是 。
。![\[\begin{aligned}Z = \sum_{y_1, \ldots, y_m} e^{C(y_1, \ldots, y_m)}\end{aligned}\]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-cb6015af097c676e348ffb4665decc75_l3.png "Rendered by QuickLaTeX.com")
 ,表示从时间步
,表示从时间步 开始、以
开始、以 为tag开始的序列,计算公式如下:
为tag开始的序列,计算公式如下:![\[\begin{aligned}Z_t(y_t) &= \sum_{y_{t+1}} e^{s_t[y_t] + T[y_{t}, y_{t+1}]} \sum_{y_{t+2}, \ldots, y_m} e^{C(y_{t+1}, \ldots, y_m)} \\&= \sum_{y_{t+1}} e^{s_t[y_t] + T[y_{t}, y_{t+1}]} \ Z_{t+1}(y_{t+1})\\\log Z_t(y_t) &= \log \sum_{y_{t+1}} e^{s_t [y_t] + T[y_{t}, y_{t+1}] + \log Z_{t+1}(y_{t+1})}\end{aligned}\]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-02a6eb62ee56a6030d8c8fd1a49a0bc9_l3.png "Rendered by QuickLaTeX.com")
![\[\begin{aligned}\mathbb{P}(y_1, \ldots, y_m) = \frac{e^{C(y_1, \ldots, y_m)}}{Z}\end{aligned}\]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-8dcee04a0c355a26c592ab3d56cf5099_l3.png "Rendered by QuickLaTeX.com")
![\[\begin{aligned}- \log (\mathbb{P}(\tilde{y}))\end{aligned}\]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-dd4a29d8d2e853b20256a0c3e4e115e8_l3.png "Rendered by QuickLaTeX.com")
 为正确的标注序列,它的概率
为正确的标注序列,它的概率 计算公式如下:
计算公式如下:
![\mathbb{P}(\tilde{y}) = \prod p_t[\tilde{y}^t]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-50e2874f55bd3b56e2eaf58feb447191_l3.png "Rendered by QuickLaTeX.com")






 这个式子来计算隐藏层,隐藏层的输入单元有两个,一个是当前时间步的输入
这个式子来计算隐藏层,隐藏层的输入单元有两个,一个是当前时间步的输入 ,另一个是上一个隐藏状态
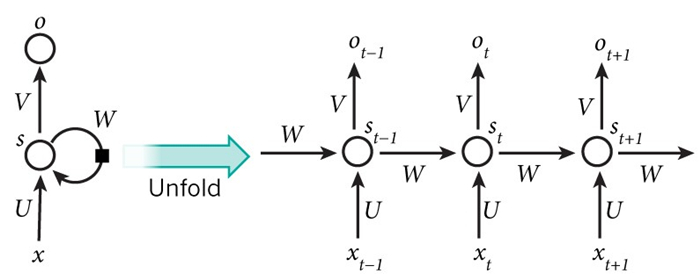
,另一个是上一个隐藏状态 。LSTM单元干的也是一样的事情,只不过换了个方式而已!这是理解LSTM的关键。现在,你最终可以把LSTM和GRU当作一个黑盒来使用,只要给你一个当前时间的输入以及上一个状态,你就可以计算出下一个状态了。正如下图:
。LSTM单元干的也是一样的事情,只不过换了个方式而已!这是理解LSTM的关键。现在,你最终可以把LSTM和GRU当作一个黑盒来使用,只要给你一个当前时间的输入以及上一个状态,你就可以计算出下一个状态了。正如下图:
 和
和 而已。在原始RNN中,我们是直接把g的值当作一个状态输出给下一个状态,在LSTM中,我们将用输入门来挑选g的一部分值,再输出给下一个状态。
而已。在原始RNN中,我们是直接把g的值当作一个状态输出给下一个状态,在LSTM中,我们将用输入门来挑选g的一部分值,再输出给下一个状态。 就是内部的记忆单元了。它是上一个记忆单元和遗忘门相乘的结果,再加上隐藏候选状态g和输入门相乘的结果。这样,我们既可以完全忘记上一个记忆单元的内容(把遗忘门全部置为0),也可以完全忽略掉新的输入状态(把输入门全部置为0),当然现实情况是我们需要的结果是这两种极端情况之间。
就是内部的记忆单元了。它是上一个记忆单元和遗忘门相乘的结果,再加上隐藏候选状态g和输入门相乘的结果。这样,我们既可以完全忘记上一个记忆单元的内容(把遗忘门全部置为0),也可以完全忽略掉新的输入状态(把输入门全部置为0),当然现实情况是我们需要的结果是这两种极端情况之间。 ,由式子可知,
,由式子可知,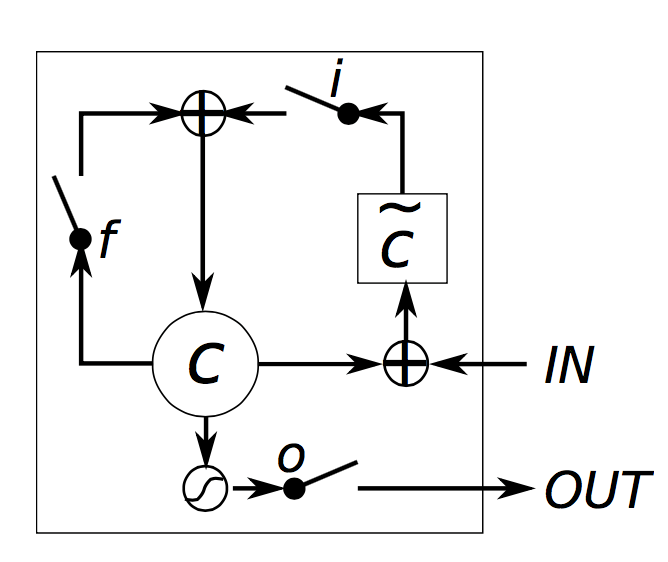
 。在门方程增加附选项即可。这篇论文(
。在门方程增加附选项即可。这篇论文(
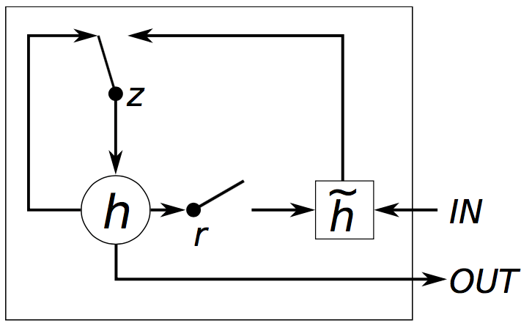

 变成了
变成了 ,这是为了和要引用的一些文献保持一致:
,这是为了和要引用的一些文献保持一致:![\[ s_{t}=\tanh(Ux_{t}+Ws_{t-1}) \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-cd017e75dc25c7da4ef8332142d2486d_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{y}_{t}=\rm softmax(Vs_{t}) \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-a78c973c8e204ea382704a04ad2914a0_l3.png "Rendered by QuickLaTeX.com")

 是正确的标签,
是正确的标签, 是我们的预测。我们以一个句子序列为一个训练样本,所以总的误差就是每一个时间步(单词)的误差和。
是我们的预测。我们以一个句子序列为一个训练样本,所以总的误差就是每一个时间步(单词)的误差和。
![\[ \frac{\partial E}{\partial W}=\sum_{t} \frac{\partial E_{t}}{\partial W} \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-6a9cb39d56edb14d307addf2647e38e1_l3.png "Rendered by QuickLaTeX.com")
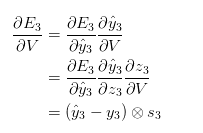
 ,
, 是外积的意思。事实上,上面这个式子的推导还是省略了几个步骤的,包括softmax函数与交叉熵结合的求导,关于里面的细节,可以参考这两篇文章:
是外积的意思。事实上,上面这个式子的推导还是省略了几个步骤的,包括softmax函数与交叉熵结合的求导,关于里面的细节,可以参考这两篇文章: 这个值,只取决于当前时间步的一些值:
这个值,只取决于当前时间步的一些值: 、
、 、
、 ,如果你有了这些值,计算关于V的梯度只是简单的矩阵乘法而已。
,如果你有了这些值,计算关于V的梯度只是简单的矩阵乘法而已。 (还有U)而言,事情就不一样了,我们来看一下链式式子:
(还有U)而言,事情就不一样了,我们来看一下链式式子:
 的值,而
的值,而 和
和 的值…依此类推。所以,如果我们想得到相对于W的导数,我们就不能把
的值…依此类推。所以,如果我们想得到相对于W的导数,我们就不能把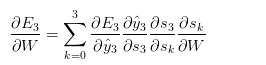
 就是一系列单词,每一个
就是一系列单词,每一个 也是类似的形式,是个8000维的数组,理论上,
也是类似的形式,是个8000维的数组,理论上,![\[ o_{t}=\rm softmax(Vs_{t}) \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-9fc43e2cf3f63785a855a6305df39855_l3.png "Rendered by QuickLaTeX.com")

 这一步。这也是我们希望词汇表越小越好的原因。
这一步。这也是我们希望词汇表越小越好的原因。![[-\frac{1}{\sqrt{n}},\frac{1}{\sqrt{n}}]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-85acd34bf6d4af7df07f74c0f5715de0_l3.png "Rendered by QuickLaTeX.com") 之内,n代表着上一层的连接数。听起来好像很复杂,不用担心,反正只要你将你的参数初始化为一个比较小的值,它通常都会挺奏效的。
之内,n代表着上一层的连接数。听起来好像很复杂,不用担心,反正只要你将你的参数初始化为一个比较小的值,它通常都会挺奏效的。 ,如下式:
,如下式:![\[ L(y,o)=-\frac{1}{N}\sum_{n\subseteq N}y_n\log{o_n} \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-96e2dc1ab6debe5611602c24badbc474_l3.png "Rendered by QuickLaTeX.com")
 是一个概率,假如
是一个概率,假如 就越接近0,损失函数的值就越小,这和上面的解释是吻合的。举个例子,比如
就越接近0,损失函数的值就越小,这和上面的解释是吻合的。举个例子,比如![y_{n}=[0,0,1]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-c720ab1226b7d95e8b4c0a80a8237e56_l3.png "Rendered by QuickLaTeX.com") ,
,![o_{n}=[0.1,0.4,0.5]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-a4cd2dc762d5a9df1b619114f313bd53_l3.png "Rendered by QuickLaTeX.com") ,
, ,看到没有,其他的0我们是可以忽略的,而且如果预测越精准(概率趋于1),
,看到没有,其他的0我们是可以忽略的,而且如果预测越精准(概率趋于1), ,也就是损失几乎为0)
,也就是损失几乎为0) ,\frac{\partial L}{\partial V},\frac{\partial L}{\partial W}
,\frac{\partial L}{\partial V},\frac{\partial L}{\partial W}
 ,
, 通常是非线性的激活函数,比如tanh或者ReLU函数。
通常是非线性的激活函数,比如tanh或者ReLU函数。



RNN.png "多层(双向)RNN")

 是权重,而
是权重,而  是偏置,
是偏置, 则是某个代价函数。第
则是某个代价函数。第 个神经元的输出 ,其中
个神经元的输出 ,其中 是激活函数,
是激活函数, 是神经元的带权输入,
是神经元的带权输入, 为对应节点的残差。
为对应节点的残差。 ,看看会发生什么。
,看看会发生什么。![\[ \frac{\partial J(W,b)}{\partial b_{i}^{l}}=\delta _{i}^{(l+1)}\qquad(4) \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-a657ffaf6f155dc785664d04e7728daa_l3.png "Rendered by QuickLaTeX.com")
![\[ \delta _{i}^{(l)} = (\sum_{j=1}^{s_{l+1}}W_{ji}^{(l)}\delta_{j}^{(l+1)})\cdot {f}'(z_{i}^{(l)})\qquad(6) \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-06d0981dd38299ad4ef1923fa4d48e99_l3.png "Rendered by QuickLaTeX.com")
 ,也就是我们上面所说的代价函数
,也就是我们上面所说的代价函数![\[ \frac{\partial C}{\partial b_1}=\delta_2 \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-c731b233d4a1467eb74505505aad46cb_l3.png "Rendered by QuickLaTeX.com")
![\[ \begin{aligned} \frac{\partial C}{\partial b_1}&=\delta_2\\ &={f}'(z_1)w_2\delta_3\\ &={f}'(z_1)w_2{f}'(z_2)w_3\delta_4\\ &={f}'(z_1)w_2{f}'(z_2)w_3{f}'(z_3)w_4\delta_5 \end{aligned} \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-f444a52a4b607571fc23dc2e70eda8ec_l3.png "Rendered by QuickLaTeX.com")
 ,就是最后一个节点的残差,由链式求导法则可知:
,就是最后一个节点的残差,由链式求导法则可知:![\[ delta_5= \frac{\partial C}{\partial a_4}{f}'(z_4) \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-2c74bfae77ded30875ce0c6c900ed5f1_l3.png "Rendered by QuickLaTeX.com")
![\[ \frac{\partial C}{\partial b_1}={f}'(z_1)w_2{f}'(z_2)w_3{f}'(z_3)w_4\frac{\partial C}{\partial a_4}{f}'(z_4) \]](https://www.lookfor404.com/wp-content/ql-cache/quicklatex.com-b9960d3b91f24bbe423d039397f12438_l3.png "Rendered by QuickLaTeX.com")
 的乘积,我们假设,这里的激活函数f用的是sigmoid函数,sigmoid的图像如下:
的乘积,我们假设,这里的激活函数f用的是sigmoid函数,sigmoid的图像如下:

 时达到最高。现在,如果我们使用标准方法来初始化网络中的权重,那么会使用一个均值0标准差为1的高斯分布。因此所有的权重通常会满足
时达到最高。现在,如果我们使用标准方法来初始化网络中的权重,那么会使用一个均值0标准差为1的高斯分布。因此所有的权重通常会满足 。有了这些信息,我们发现会有
。有了这些信息,我们发现会有 。并且在我们进行了所有这些项的乘积时,最终结果肯定会指数级下降:项越多,乘积的下降的越快。 这,就是梯度消失出现的原因。 同样的,如果我们选择不同的权重初始化方法、以及不同的激活函数,我们也有可能得到
。并且在我们进行了所有这些项的乘积时,最终结果肯定会指数级下降:项越多,乘积的下降的越快。 这,就是梯度消失出现的原因。 同样的,如果我们选择不同的权重初始化方法、以及不同的激活函数,我们也有可能得到 的结果,经过多层累乘,梯度会迅速增长,造成梯度爆炸。
的结果,经过多层累乘,梯度会迅速增长,造成梯度爆炸。